**出典: **AIGC オープン コミュニティ9月14日、有名なオープンソースプラットフォームのStability AIは、音声生成AI製品「Stable Audio」を公式ウェブサイトでリリースした。 (無料使用アドレス:ユーザーは、ロック、ジャズ、エレクトロニック、ヒップホップ、ヘヴィメタル、フォーク、ポップ、パンク、カントリーなど、20 種類以上の BGM をテキスト プロンプトを通じて直接生成できます。たとえば、ディスコ、ドラムマシン、シンセサイザー、ベース、ピアノ、ギター、陽気、115 BPM などのキーワードを入力して、BGM を生成します。現在、Stable Audio には 2 つの無料バージョンと有料バージョンがあります。無料バージョンは、月あたり 20 曲、最長 45 秒の音楽を生成でき、商業目的での使用はできません。有料バージョンは、月額 11.99 ドルかかります (約87元)、500曲の音楽を生成でき、音楽は最大90秒間、商用利用可能です。支払いたくない場合は、さらにいくつかのアカウントを登録し、生成された音楽を AU (オーディオ エディター) または PR を介してつなぎ合わせて、同じ効果を得ることができます。## Stable Audio の簡単な紹介過去数年間で、拡散モデルは画像、ビデオ、オーディオ、その他の分野で急速な発展を遂げ、トレーニングと推論の効率を大幅に向上させることができました。しかし、オーディオ領域の拡散モデルには問題があり、通常、固定サイズのコンテンツが生成されます。たとえば、オーディオ拡散モデルは 30 秒のオーディオ クリップでトレーニングされ、30 秒のオーディオ クリップのみを生成する場合があります。この技術的なボトルネックを解消するために、Stable Audio はより高度なモデルを使用しています。これは、テキスト メタデータとオーディオ ファイルの長さと開始時間の調整に基づいたオーディオ潜在拡散モデルであり、生成されるオーディオのコンテンツと長さを制御できます。この追加の時間条件により、ユーザーは指定された長さのオーディオを生成できます。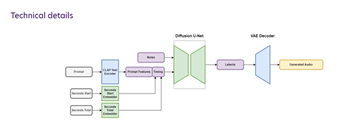 大幅にダウンサンプリングされたオーディオの潜在表現を使用すると、元のオーディオと比較してより高速な推論効率を達成できます。最新の安定したオーディオ モデルを使用すると、Stable Audio は、NVIDIA A100 GPU を使用して、サンプリング レート 44.1 kHz で 95 秒のステレオ オーディオを 1 秒未満でレンダリングできます。トレーニング データに関しては、Stable Audio は音楽、効果音、さまざまな楽器を含む 800,000 を超えるオーディオ ファイルで構成されるデータ セットを使用します。データセットは合計19,500時間以上の音声を収録しており、音楽サービスプロバイダーAudioSparxとも連携しているため、生成された音楽は商品化にも利用可能だ。## 潜在拡散モデルStable Audio で使用される潜在拡散モデルは、主に事前トレーニングされたオートエンコーダーの潜在エンコード空間で使用される拡散ベースの生成モデルです。これは、オートエンコーダーと拡散モデルを組み合わせたアプローチです。オートエンコーダーは、まず入力データ (画像や音声など) の低次元の潜在表現を学習するために使用されます。この潜在的な表現は入力データの重要な特徴を捉えており、元のデータを再構築するために使用できます。次に、拡散モデルはこの潜在空間でトレーニングされ、潜在変数を徐々に変更して新しいデータを生成します。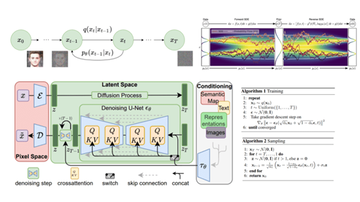 このアプローチの主な利点は、拡散モデルのトレーニングと推論の速度を大幅に向上できることです。拡散プロセスは元のデータ空間ではなく比較的小さな潜在空間で発生するため、新しいデータをより効率的に生成できます。さらに、このようなモデルは潜在空間で動作することにより、生成されたデータをより適切に制御することもできます。たとえば、潜在変数を操作して、生成されたデータの特定の特性を変更したり、潜在変数に制約を課すことによってデータ生成プロセスを誘導したりできます。## 安定したオーディオの使用とケースの表示「AIGC Open Community」でStable Audioの無料版を試してみました 使用方法はChatGPTと同様で、テキストプロンプトを入力するだけです。プロンプト コンテンツには、詳細、メンタリティ、楽器、ビートの 4 つのカテゴリが含まれます。生成される音楽をより繊細でリズミカルにしたい場合は、入力テキストもより詳細にする必要があることに注意してください。つまり、入力するテキスト プロンプトの数が多いほど、生成される効果は向上します。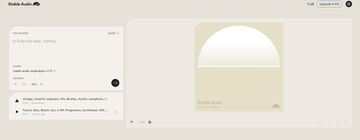 安定したオーディオのユーザーインターフェイス以下は、オーディオを生成するケースのデモンストレーションです。トランス、アイランド、ビーチ、太陽、午前 4 時、プログレッシブ、シンセ、909、ドラマチックなコード、コーラス、アップビート、ノスタルジック、ダイナミック。柔らかな抱擁、快適さ、低音シンセ、きらめき、風と葉、アンビエント、平和、リラックス、水。ポップエレクトロニック、大きなリバーブシンセ、ドラムマシン、雰囲気のある、ムーディーな、ノスタルジックな、クールな、ポップなインストゥルメンタル、100 BPM。3/4、3 ビート、ギター、ドラム、明るい、楽しい、手拍子この記事の素材はStability AIの公式ウェブサイトからのものです。侵害がある場合は、削除するために当社までご連絡ください。終わり


テキストから直接20種類以上のBGMを生成できるStable Audioの無料版が登場!
**出典: **AIGC オープン コミュニティ
9月14日、有名なオープンソースプラットフォームのStability AIは、音声生成AI製品「Stable Audio」を公式ウェブサイトでリリースした。 (無料使用アドレス:
ユーザーは、ロック、ジャズ、エレクトロニック、ヒップホップ、ヘヴィメタル、フォーク、ポップ、パンク、カントリーなど、20 種類以上の BGM をテキスト プロンプトを通じて直接生成できます。
たとえば、ディスコ、ドラムマシン、シンセサイザー、ベース、ピアノ、ギター、陽気、115 BPM などのキーワードを入力して、BGM を生成します。
現在、Stable Audio には 2 つの無料バージョンと有料バージョンがあります。無料バージョンは、月あたり 20 曲、最長 45 秒の音楽を生成でき、商業目的での使用はできません。有料バージョンは、月額 11.99 ドルかかります (約87元)、500曲の音楽を生成でき、音楽は最大90秒間、商用利用可能です。
支払いたくない場合は、さらにいくつかのアカウントを登録し、生成された音楽を AU (オーディオ エディター) または PR を介してつなぎ合わせて、同じ効果を得ることができます。
Stable Audio の簡単な紹介
過去数年間で、拡散モデルは画像、ビデオ、オーディオ、その他の分野で急速な発展を遂げ、トレーニングと推論の効率を大幅に向上させることができました。しかし、オーディオ領域の拡散モデルには問題があり、通常、固定サイズのコンテンツが生成されます。
たとえば、オーディオ拡散モデルは 30 秒のオーディオ クリップでトレーニングされ、30 秒のオーディオ クリップのみを生成する場合があります。この技術的なボトルネックを解消するために、Stable Audio はより高度なモデルを使用しています。
これは、テキスト メタデータとオーディオ ファイルの長さと開始時間の調整に基づいたオーディオ潜在拡散モデルであり、生成されるオーディオのコンテンツと長さを制御できます。この追加の時間条件により、ユーザーは指定された長さのオーディオを生成できます。
トレーニング データに関しては、Stable Audio は音楽、効果音、さまざまな楽器を含む 800,000 を超えるオーディオ ファイルで構成されるデータ セットを使用します。
データセットは合計19,500時間以上の音声を収録しており、音楽サービスプロバイダーAudioSparxとも連携しているため、生成された音楽は商品化にも利用可能だ。
潜在拡散モデル
Stable Audio で使用される潜在拡散モデルは、主に事前トレーニングされたオートエンコーダーの潜在エンコード空間で使用される拡散ベースの生成モデルです。これは、オートエンコーダーと拡散モデルを組み合わせたアプローチです。
オートエンコーダーは、まず入力データ (画像や音声など) の低次元の潜在表現を学習するために使用されます。この潜在的な表現は入力データの重要な特徴を捉えており、元のデータを再構築するために使用できます。
次に、拡散モデルはこの潜在空間でトレーニングされ、潜在変数を徐々に変更して新しいデータを生成します。
さらに、このようなモデルは潜在空間で動作することにより、生成されたデータをより適切に制御することもできます。たとえば、潜在変数を操作して、生成されたデータの特定の特性を変更したり、潜在変数に制約を課すことによってデータ生成プロセスを誘導したりできます。
安定したオーディオの使用とケースの表示
「AIGC Open Community」でStable Audioの無料版を試してみました 使用方法はChatGPTと同様で、テキストプロンプトを入力するだけです。プロンプト コンテンツには、詳細、メンタリティ、楽器、ビートの 4 つのカテゴリが含まれます。
生成される音楽をより繊細でリズミカルにしたい場合は、入力テキストもより詳細にする必要があることに注意してください。つまり、入力するテキスト プロンプトの数が多いほど、生成される効果は向上します。
以下は、オーディオを生成するケースのデモンストレーションです。
トランス、アイランド、ビーチ、太陽、午前 4 時、プログレッシブ、シンセ、909、ドラマチックなコード、コーラス、アップビート、ノスタルジック、ダイナミック。
柔らかな抱擁、快適さ、低音シンセ、きらめき、風と葉、アンビエント、平和、リラックス、水。
ポップエレクトロニック、大きなリバーブシンセ、ドラムマシン、雰囲気のある、ムーディーな、ノスタルジックな、クールな、ポップなインストゥルメンタル、100 BPM。
3/4、3 ビート、ギター、ドラム、明るい、楽しい、手拍子
この記事の素材はStability AIの公式ウェブサイトからのものです。侵害がある場合は、削除するために当社までご連絡ください。
終わり